Going multi-model with PostgreSQL and Apache AGE: experimenting with Graph Databases
Let's explore the many kinds of databases available and experiment with graph models using PostgreSQL and Apache AGE

The Database landscape
When talking about Databases, for the majority of people the first thought goes to classic Relational Databases, or the SQL Databases as they are often referred to. In these Databases data is stored in rows and columns inside Tables that could be related via foreign keys, that are one or more columns that link back to the primary key (aka the ID) of the rows in another table.
The Relational Databases have been the norm for the last fifty years almost, but in recent years other kind of Databases have emerged to tackle with specific use cases in which the relational model could show its limits (mainly with performance and scalability).
In the last fifteen years many different type of Databases have been created in the form of Columnar Databases (like AWS Dynamo DB or Apache Cassandra for example), Document Databases (MongoDB or CouchDB) and Graph Databases (Neo4J).
Each of these new forms of Database have been created to better suit the needs of specific application domains and to increase the performance and scalability of traditional relational systems.
Why a Graph Database
Relational database are good for modeling pretty much every application domain if we talk about storing the data and being able to query it. But there are contexts in which the relational model is not the best choice in terms of performance or complexity. These are the contexts in which the relationships have the same or even greater meaning that the entities themselves.
Let's borrow an example from the book Graph Databases 2nd edition (you can grab a copy of it from the Neo4J website) about the context of a datacenter domain.
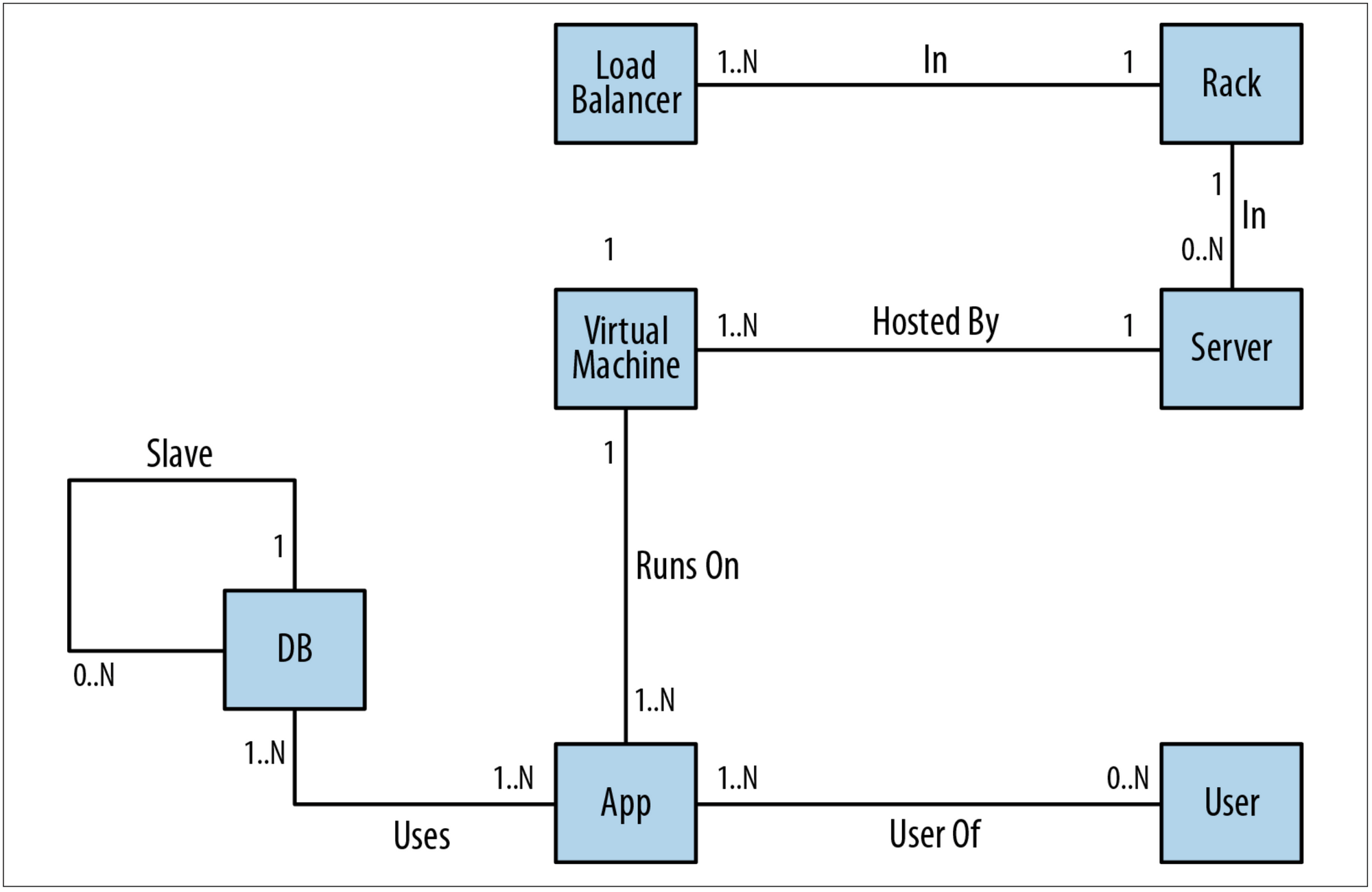
This is still a pretty simple domain context but it has a sufficient number of entities and relationships to start making the queries on a traditional datbase big and slow.
Here is a possible modeling of the keys and relations on the previous ER model
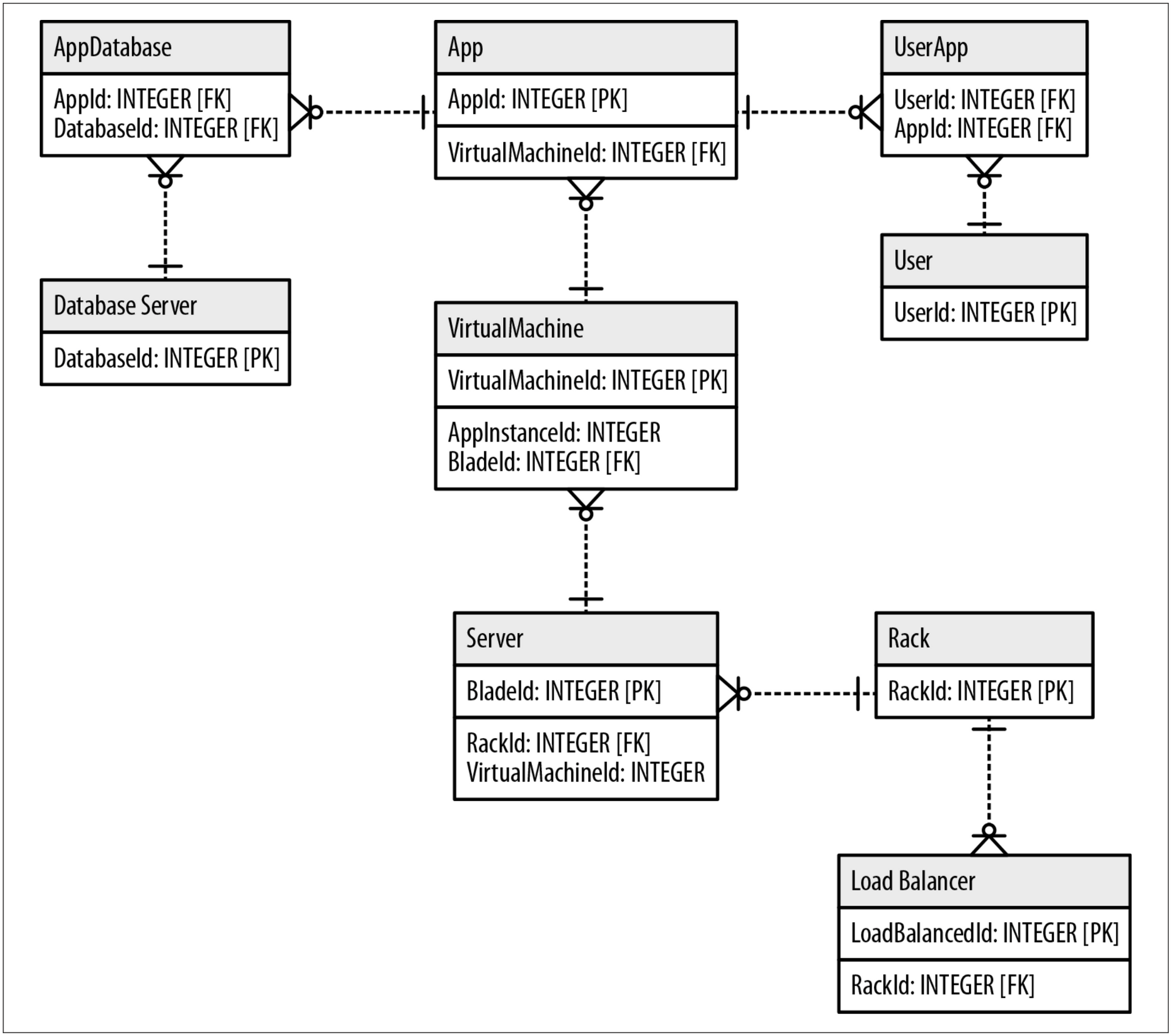
Now let's try to imagine a query that looks for the users impacted by the failure of one of the components of the infrastructure (Server, Load Balancer, Database and so on). You could end up with a monster query with many JOINs or with a lot of small queries each looking to a particular asset inside the model. Of course we will be able to get the answer to our question, but probably performance could become an issue, especially then the number of assets starts to grow.
Now let's try to model the previous domain as a Graph with assets and relations between them.
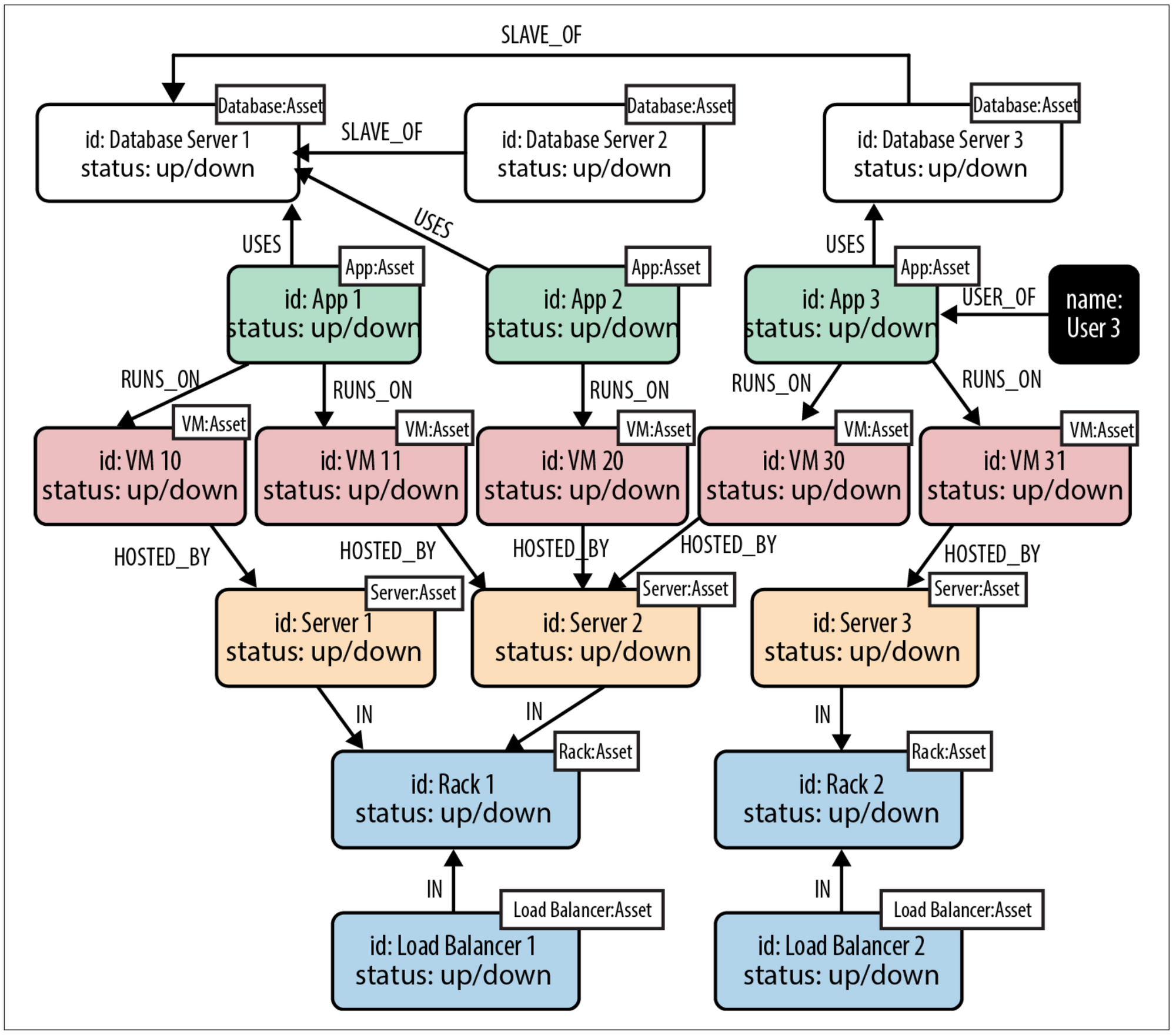
The first thing you can notice is that now relationships have become "first class citizens" inside the model, meaning that now every arrow has a specific meaning like HOSTED_BY, RUNS_ON, USES, USER_OF and so on. This allows the model to be more expressive just by looking to the diagram. In the relational model you only know that a table is linked to another but the meaning of that relationship could be difficult to get.
If now for example user User 3 of the previous image reports a problem, we can query the graph to find any possible asset involved by issuing the following query:
MATCH (user:User)-[*1..5]-(asset:Asset)
WHERE user.name = 'User 3' AND asset.status = 'down'
RETURN DISTINCT assetWait... what kind of query is that?!? It's a query language called Cypher and introduced by Neo4J that is designed to query graphs in an easy way. It's defined as "some sort of ASCIIart to navigate the graph".
The previous query translated in plain english says the following: Look for any User named 'User 3' connected by one to five degrees of relationship with an Asset whose state is 'down' then return the list of distinct assets found.
If you think to the same in SQL... is it even possible? Probabily yes, but not in such a short and expressive way. Now you should be starting to get the point of a graph model.
Neo4J
We previously talked about Neo4J as a graph database and for a good reason, it is the most widely known graph database on the market and it has been around for more than ten years now, so it is pretty solid and battle tested.
But if I have to find something I don't like in Neo4J, it's Graph Only, so there is no "smooth transition" from a traditional relational Database, and if you have some piece of software already written you have to rewrite everything to use the new data model. In addition to this, Neo4J is written in Java, and even if I use Java everyday for application development, I'm biased to think that a Database written in Java could be a bit memory hungry.
Don't get me wrong, Neo4J is still the best option if you need to go for a graph only data model, it has a lot of features and if you need support there is enterprise support from the company that develops it.
An hybrid approach
I want to introduce the power of a graph database inside my application, but as everything, there is no one-size-fits-all, and graph database are no exception, they are good for graph traversal but they are not the best option for every possible scenario.
The requirements of an application can span widely sometimes and it could be useful to have the best of all worlds when talking about database, so one part of the data model as a graph, another as a group of tables and maybe another inside a document collection. The problem is that I don't like the idea of having many different database engines in the same application.
Could there be a solution to that?
PostgreSQL and Apache AGE
PostgreSQL is a well known name in the database landscape and for many good reasons. To name a few, it is one of the most powerful Open Source databases available and it is rock solid and performant at the same time. There are examples of PostgreSQL databases of tens of TeraBytes.
One of the nice aspects of PostgreSQL is that it allows the use of extensions to augment the capabilities of the database itself, and there are a lot of powerful extensions that allow PostgreSQL to span many different contexts. Example of extensions are:
- TimescaleDB : an extension to deal with time series and windowing
- PostGIS : an extension to work with Geographical Information Systems (GIS), that allows to work with coordinates an geospatial calculations
- ZomboDB : an extension to enhance full text search capabilities of PostgreSQL while integrating with Elasticsearch
Apache AGE (in which AGE stands for "A Graph Extension") is another of these extensions and it's a sort of bridge between worlds of relational, document and graph databases, leveraging the stability and solidity of the PostgreSQL database while enhancing its capabilities with the power of a Graph Database.
AGE is still in Apache Incubator, meaning it's still in the early phases of development (the current version i 0.7), but it is based on the work done by BitNine's AgensGraph even if following a different approach. AgensGraph is a commercial graph database built on a fork of PostgreSQL 10, while Apache AGE is built as an extension to the standard PostgreSQL (at the moment of writing it supports version 11, but support for newer releases is expected in 2022) so it can be used as an "upgrade" to the standard features without loosing the rest.
The good about this approach, is that you can mix the features of a relational model with the ones of a graph databasee, meaning that you can mix together SQL queries on tables with OpenCyhpher queries on graphs.
If you think that PostgreSQL also has support for JSON and JSONB datatypes so that you can also have part of the features of a Document Database, you can understand why this hybrid solution could be a good option.
Let's see how we can start playing with Apache AGE with Docker, then in the next post we will see some of the features of OpenCyhper and the integration with the standard relational world.
Getting started with Apache AGE using Docker
The fastest way to get started with Apache AGE is to run it in a prebuilt Docker container, and you can do it with the following command:
docker run -it -e POSTGRES_PASSWORD={MyPassword} -p {HostPort}:5432 sorrell/apache-ageThis is the "official" Docker image but at the time of writing it is three months old, so it doesn't have all the recently added features and bug fixes. To test all of the features let's build a new image using the latest sources from the GitHub repo.
Building the latest release from sources using Docker
 apache
apacheYou can think that building a Docker image from the sources could be a complex process, but in reality it is very easy, just clone the repository on your machine with the following commands:
git clone https://github.com/apache/incubator-age.git
cd incubator-ageand tell Docker to build the image:
docker build -t apache/age .After a couple of minutes (depending on the speed of your network connection and the power of your computer) the process should complete.
Launching an AGE instance with Docker
To start an instance of the newly built image with PostgreSQL 11 and the AGE extension you can run the following command:
docker run -it -e POSTGRES_PASSWORD=mypassword -p 5432:5432 apache/ageAs soon as the container starts you are ready to connect to the database and start playing with SQL and OpenCypher.
If you prefer to have some graphical representation of the output of your queries, you can also experiment with the AGE Viewer, a node.js application (in early stages of development) that allows you to query and navigate the results in a graphical or tabular way directly inside the browser.
apacheConnecting to the database
Another nice aspect of using Apache AGE is that you are daling with a standard PostgreSQL database, so to connect to it you can use the standard psql command line client
psql -h 0.0.0.0 -p 5432 -U postgresor your preferred SQL client, like DBeaver.
In case it's not automatically loaded at startup, you can enable the AGE extension by issuing the following SQL commands:
CREATE EXTENSION IF NOT EXISTS age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;Now you are ready to start using your new graph database.
Create a Graph
The first thing you need to do to start playing with a grap model is... to create a graph. You can do it with the create_graph('GRAPH_NAME') function:
SELECT create_graph('my_graph_name');Once the graph is created you can execute Cypher commands using the cypher('GRAPH_NAME', QUERY) function like the following:
SELECT * from cypher('my_graph_name', $$
CypherQuery
$$) as (a agtype);For example to create a node (or Vertex in the graph language) you can run:
SELECT * from cypher('my_graph_name', $$
CREATE (a:User { firstName: 'Fabio', lastName: 'Marini'})
RETURN a
$$) as (a agtype);This creates a vertex with a label User and the firstName and lastName properties. Another good aspect of a graph database is that both Vertexes and Edges can contain properties that you can dynamically add and query.
We have just scratched the surface of what we can do with a graph database, you can have a look at the AGE's documentation to understand the features and the syntax of the OpenCypher query language
Next steps
In the next article we will see how to maipulate the graph model and how to query it.